Architecting Data Lakes on Object Storage: Best Practices for ETL Pipelines
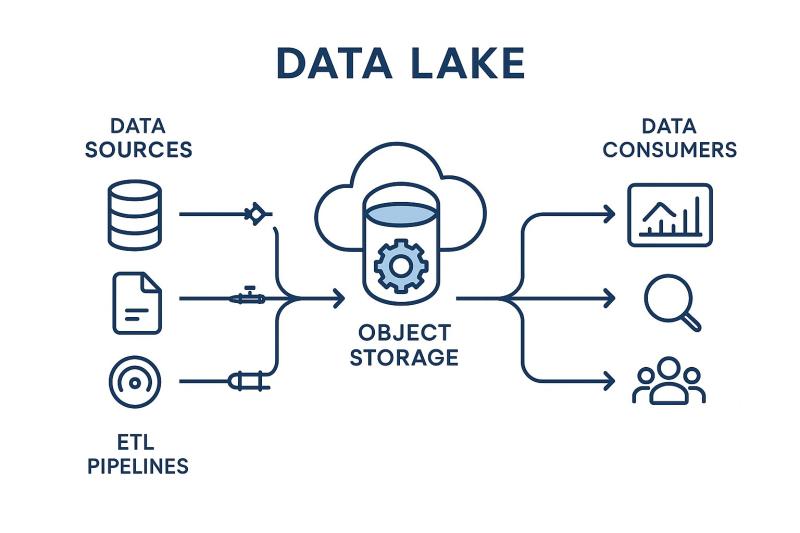
Data lakes on object storage have changed the way I approach large-scale data projects. They offer flexibility, affordability and scale that traditional systems struggle to match. If you’re building or optimizing ETL pipelines you’ll quickly realize why this combination is becoming the default architecture for modern data teams.
In this article I’ll share practical insights on how to design ETL pipelines that truly work with object storage. I’ll also highlight pitfalls I’ve seen teams run into and the best practices that keep projects on track.
Why Data Lakes on Object Storage Matter
Data lakes on object storage give us one critical advantage: room to grow without breaking budgets. Unlike rigid databases or warehouses, object storage lets us store structured, semi-structured and unstructured data in a single place.
That means logs from your applications, clickstream data from your website or even sensor data from IoT devices can live side by side. With ETL object storage pipelines layered on top, all this raw data gets transformed into formats ready for analysis or machine learning.
When I first started working with object storage the biggest win was how it removed the fear of running out of capacity. For most of us in data engineering that’s a huge relief.
The Role of ETL in Object Storage Pipelines
ETL object storage workflows are what make data lakes usable. Raw data by itself doesn’t help much unless it’s extracted, cleaned and organized.
ETL pipelines handle that process by pulling data from multiple systems, transforming it into usable formats and loading it into analytics platforms. In older setups ETL was slow and bound by limited infrastructure. But now with compute separated from storage we can process massive datasets in parallel.
That means faster insights whether you’re running real-time fraud detection or training an ML model on historical data.
Best Practices I Recommend for Pipeline Design
1. Optimize Your Ingestion Strategy
When I build pipelines for data lakes on object storage, ingestion is the first thing I focus on. Real-time sources need tools like Kafka or Kinesis. Batch ingestion works fine for nightly loads but you need to schedule it carefully to avoid overwhelming your systems.
2. Use Schema-on-Read
Unlike traditional warehouses, schema-on-read lets you store raw data without deciding on a schema upfront. It speeds up ingestion and gives you more flexibility later. Trust me, this has saved me countless hours when business requirements changed unexpectedly.
3. Automate Metadata Management
If you don’t track what you’ve ingested your data lake can quickly turn into a swamp. I’ve learned to automate tagging and cataloging using services like AWS Glue or open-source catalogs. It keeps data discoverable for teams down the line. If you’re using S3 or S3-compatible stores, check out this hands-on guide for more details: A Complete Guide to Amazon S3 for Cloud Storage.
4. Partition and Index the Right Way
Partitioning your object storage buckets by time or region speeds up queries. Indexing frequently accessed datasets is equally important. I’ve seen teams skip this step and pay the price with painfully slow analytics later.
5. Lean on Parallel Processing
When transformations get heavy, distribute the load. Frameworks like Apache Spark or Dask let you run jobs across clusters instead of one overloaded machine. For me this was the game-changer that kept pipelines running smoothly even as data volumes exploded.
6. Take Security Seriously
Object storage may be flexible but don’t forget governance. I always enforce encryption, strict access policies and audit logs. Many industries have compliance rules that don’t forgive shortcuts.
7. Monitor and Optimize Continuously
Pipelines aren’t a set-and-forget system. I’ve built monitoring into every stage to catch errors, track throughput and measure latency. Small tweaks often save hours of debugging later.
Common Issues I’ve Seen (and How to Avoid Them)
Even with the best setup I’ve run into recurring challenges:
- Data duplication inflating costs and confusing analytics
- Uncontrolled growth that turns a neat lake into a dumping ground
- Latency problems when queries hit poorly partitioned buckets
- Tooling gaps where legacy ETL tools don’t work well with object storage
The fix is usually planning, designing pipelines with governance, scalability and performance in mind rather than treating them as an afterthought.
Real-World Scenarios
To make this more concrete, here are a few places where I’ve seen well-architected data lakes on object storage shine:
- Retail analytics: bringing together sales, supply chain and customer data for better forecasting
- Healthcare: managing huge medical imaging datasets securely while running predictive diagnosis models
- Finance: enabling near real-time fraud detection with fast-moving data streams
- AI/ML: feeding consistent and high-quality data into training pipelines without delay
Each of these depends on a solid data pipeline design, not just cheap storage.
Are You Ready to TakeNext Steps?
If you’re serious about scaling analytics or AI, data lakes on object storage are worth the investment. Pairing them with the right ETL pipeline design means you can manage growth without chaos, deliver insights faster and stay ahead of compliance requirements.
I’ve learned that the most successful projects aren’t just about technology, they’re about discipline in following best practices.
If you’re currently building or optimizing your data pipelines, start small, focus on metadata and governance and test for performance early. You’ll thank yourself later when the system scales without breaking.
If you want to explore more hands-on frameworks or examples, feel free to comment below. Together we can make sure your data lake becomes a competitive advantage, not a headache.

Comments